Fairness, Accountability &
Transparency (F.Acc.T)
under GDPR




Why the need for Regulation?
Algorithmic decisions are already crucially affecting our lives. The last few year, news like the ones listed below are becoming more and more common:
- “There’s software used across the country to predict future criminals. And it’s biased against blacks”, 2016 [source: ProPublica].
- “Amazon reportedly scraps internal AI recruiting tool that was biased against women”, 2018 [source: The Verge]
- “Is an Algorithm Less Racist Than a Loan Officer?”, 2020 [source: NY Times]
The above indicate why we see a rise to new regulations and laws that aim to control to some extent the growing power of the algorithms. One of the first and most well-known regulations is the General Data Protection Regulation (GDPR) introduced by the European Parliament and Council of the European Union in May, 2016.
In this article, we will focus on how the properties of Fairness, Accountability and Transparency (better known as F.Acc.T) are reflected in the GDPR and we will examine the scope of the restrictions they impose on the public and private sector.
Principles of GDPR
lawfulness, fairness, transparency, purpose limitation, data minimisation, accuracy, storage limitation, integrity, confidentiality and accountability
While the F.Acc.T properties are clearly listed as principles, we need to take a deeper look in the GDPR text to understand what these terms actually mean.
Transparency under the GDPR
![Image 1: Contradicting papers [3, 4] about the right to explanation](https://code4thought.eu/wp-content/uploads/2022/06/transparency-medium.png)
The epicentre of this debate is located in Article 22 (3) GDPR,where it is stated that: “[…]the data controller shall implement suitable measures to safeguard the data subject’s rights and freedoms and legitimate interests, at least the right to obtain human intervention on the part of the controller, to express his or her point of view and to contest the decision”. Here, it is not written explicitly if the right to an explanation exists.
However, in Recital 71 GDPR, it is stated categorically that (inter alia) this right exists: “[…] such processing should be subject to suitable safeguards, which should include specific information to the data subject and the right to obtain human intervention, to express his or her point of view, to obtain an explanation of the decision reached after such assessment and to challenge the decision.”.
There is another conflicting point: Article 15 (1)(h) states the data controller should provide to the data subject “meaningful information about the logic involved”.
- Some scholars [3, 4] interpret that the “meaningful information” refers only to the model’s general structure, hence the explanations for individual predictions are not necessary.
- Other scholars [5] believe that in order for the information to be meaningful it needs to allow the data subjects to exercise their rights defined by Article 22(3), which is the right to “express his or her point of view and to contest the decision”. Since explanations provide this ability, it is argued that they must be presented.
Loophole in the system
However, even in the best case scenario, where everyone agrees that the right to explanations exists in the GDPR, the regulation states that it is referring only to “decisions based solely on automated processing” (Article 22 (1)). This means that any kind of human intervention in the decision, exempts the controller from the obligation of providing explanations. For example, if a creditor uses an automated credit scoring system only as advisory and in the end they are the ones to take the final decision for the credit applicant, then in this case GDPR does not force the system to provide explanations to the creditor as well as to the applicant.
code4thought’s stance
We believe that explanations are essential to ensure transparency and trust across all kinds of stakeholders of an algorithmic system. From our experience, users of advisory automated systems usually are prone to follow the system’s decision, even when sometimes the decision does not make much sense. From faithfully following erroneous Google Maps directions to judges using racially biased risk assessments tools, the immense power of today’s algorithmic systems tends to overthrow people’s ability for critical thinking and as a result it takes its place.
So, regardless of human intervention, we firmly believe that when algorithmic systems affect real people, explanations are necessary as they establish trust between the system and the data controllers as well as the data subjects. Moreover, they can scrutinize the algorithms for systematic bias, consequently increasing fairness. Last but not least, understanding the algorithm’s reasoning can be very helpful for debugging/tuning purposes, while in other cases (e.g. for medical diagnosis) it is imperative.
Artificial Intelligence (AI) as a “black-box”
The intricate and obscure inner structure of the most common AI model (e.g. deep neural nets, ensemble methods, GANs, etc.) forces us more often than not to treat them as “black-boxes”, that is, getting their predictions in a no-questions-asked policy. As mentioned above, this can lead erroneous behavior of the models, which may be caused by undesired patterns in our data. Explanations help us detect such patterns: in Image 2 we observe a photo of a man (lead singer of “Green Day”, B.J. Armstrong), who was falsely classified as a “Female” by a gender recognition “black-box” model. The explanation shows us that the (red) pixels representing the make-up around his eyes contributed heavily towards predicting him as “Female”, suggesting that our model chose the gender of a picture solely by detecting make-up or the not appearance of a moustache. This discovery would motivate us to take a closer look to our training data and update them.

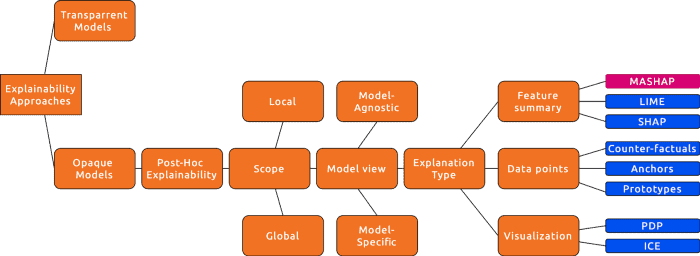
Explainability methods
There are various explainability methods and Image 3 presents a taxonomy of them. One of iQ4AI’s transparency tools is called MASHAP, which is a model-agnostic method that outputs feature summary in both local and global scope.
Fairness under the GDPR
Fairness might be the most difficult principle to define, since determining what is fair is a very subjective process, which varies from culture to culture. Asking ten different philosophers what defines fairness, the result would probably be ten different answers.
Even the translation of the word “fair” in various european languages is not straight-forward, where two or three different words are used, each referring to slightly different nuances. For example, in the German text, across different articles and recitals, “fair” is translated as “nach Treu un Glaube”, “faire” or “gerecht”.
In the context of GDPR, scholars believe that fairness can have many possible nuances, such as non-discrimination, fair balancing, procedural fairness, etc. [1, 2]. Fairness as non-discrimination refers to the elimination of “[…] discriminatory effects on natural persons on the basis of racial or ethnic origin, political opinion, religion or beliefs, trade union membership, genetic or health status or sexual orientation, or processing that results in measures having such an effect” as defined in Recital 71 GDPR. Procedural fairness is linked with timeliness, transparency and burden of care by data controllers [1]. Fair balancing is based on proportionality between interests and necessity of purposes [1, 2].
code4thought’s stance
In code4thought, we strive to pinpoint discriminatory behavior in algorithmic systems based on proportional disparities in their outcomes, so our notion of fairness is adjacent with the non-discimination and fair-balancing concepts of GDPR. More specifically, we try to examine if an algorithmic system is biased against a specific protected group of people by measuring, if the system favors one group over another for a specific outcome (e.g. Apple Card giving higher credit to male customers than female ones).
While there is a plethora of metrics for measuring fairness and various open-source toolkits containing such metrics (e.g. IBM’s AIF360, Aequitas by the University of Chicago), we choose the Disparate Impact Ratio (DIR) as our general fairness metric, which is a “ratio of ratios”, i.e. the proportion of individuals that receive a certain outcome for two groups.
The reason behind this choice is the fact that DIR is usually connected with a well-known regulatory rule, called the “four-fifths-rule” introduced by the U.S. Equal Employment Opportunity Commission (EEOC) in 29 C.F.R. § 1607.4(D) published in July 2018, rendering the metric in a way as an industry standard. Ideally the DIR should be equal to one (i.e. equal proportions for all the groups that are selected for a certain outcome). However according to the aforementioned rule, any value of DIR below 80% can be regarded as “evidence of adverse impact”. Since DIR is a fraction and the denominator might be larger than the numerator, we consider an acceptable range of DIR from 80% to 120%.
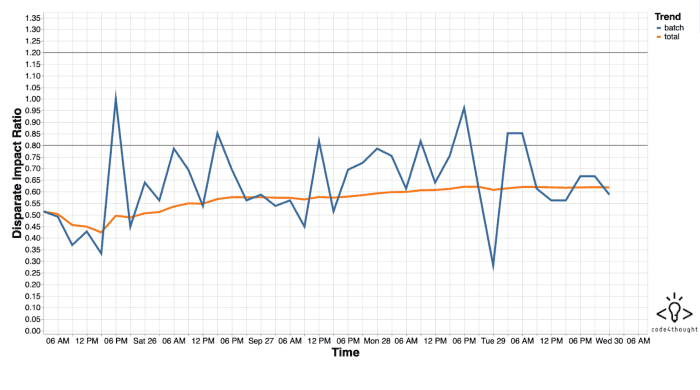
In Image 4, a screenshot of our iQ4AI monitoring tool is displayed, measuring the DIR across time of Twitter’s internal algorithm of selecting preview photos indicating possible bias (see our article for more information).
Accountability under the GDPR
Authority is increasingly expressed algorithmically and decisions that used to be based on human intuition and reaction are now automated. Data controllers should be able to guide or restrain their algorithms when necessary.
Article 24(2) GDPR mentions that “[..] the controller shall implement appropriate technical and organisational measures to ensure and to be able to demonstrate that processing is performed in accordance with this Regulation”. Also in Article 5(2) it stated that “The controller shall be responsible for, and be able to demonstrate compliance with, paragraph 1 (‘accountability’).”
Imposing accountability in algorithmic systems is not as technically challenging as fairness or transparency. It can be accomplished through the use of evaluation frameworks, in the form of simple check-lists and questionnaires that require input from experts that build or manage the system.
In July 2020 the High-Level Expert Group on Artificial Intelligence (AI HLEG) appointed by the European Union has created an assessment list for trustworthy AI. Prior to that, code4thought had published in an academic conference a similar (but less broad) assessment framework for algorithmic accountability in 2019.
Final Thoughts
We presented how the F.Acc.T principles are viewed through the lenses of GDPR. It is clear that besides the technical challenges of incorporating these principles in an algorithmic pipeline, the legal view of their imposition is also in some areas obscure (e.g. transparency).
At code4thought, we hope that the legal gaps will be filled and the related conflicts will be resolved soon, thereby creating more clear and explicit guidelines and regulations for AI Ethics. But until then, we urge organisations to proactively care about the “F.Acc.T-ness” of their algorithmic systems, since we strongly believe that it can boost their trustworthiness and yield to more stable, responsible algorithmic systems and perhaps a more fair society.
It should be noted that globally there also other similar regulations for data privacy and protection, some of which are listed below:
- Personal Information Protection and Electronic Documents Act (PIPEDA) by the Parliament of Canada in 2001
- California Consumer Privacy Act (CCPA) by California State Legislature in June, 2018
- Brazilian General Data Protection Law (Lei Geral de Proteção de Dados or LGPD) passed in 2018
- White paper οn Artificial Intelligence — A European approach to excellence and trust by the European Union in February, 2020
- Denmark’s legislation about AI & Data Ethics being the first country in Europe to implement such laws in May, 2020